
How to make a PyTorch Transformer for time series forecasting
This post will show you how to transform a time series Transformer architecture diagram into PyTorch code step by step.
towardsdatascience.com
시계열 데이터를 다뤄본적은 별로 없어서 위의 듀토리얼을 따라하면서 공부해보고자 한다. 본 포스팅은 위 원본의 요약 + 번역글이다. 이번 예제에서는 날씨 데이터를 이용하여 기상 예측을 해보고자 한다.
Overall Architecture

기본적인 모델 구조는 다음과 같다. 인코더-디코더로 이루어져있는 트랜스포머 모델을 이용하여 딥러닝을 진행할 것인데, 더 자세한 모델 구조는 아래와 같다.
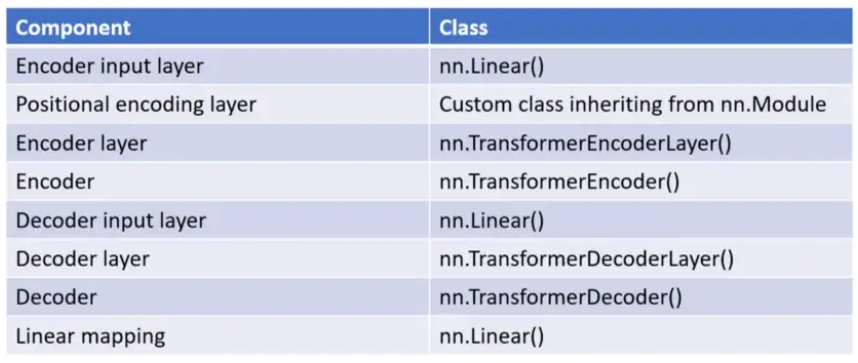
위의 fig.1에서 잘못 그려져 있는것이, input layer와 pos embedding, 그리고 linear mapping이 인코더 디코더 안에 들어가 있는 것처럼 그려져 있지만 원본 논문(Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case)에서는 따로 분리되어있어 분리해서 생각하면 된다.
Encoder input layer
Encoder input layer는 nn.Linear()로 되어있다.
self.encoder_input_layer = nn.Linear(
in_features=input_size, # 1
out_features=dim_val # 512
)Positional Encoding layer
import torch
import torch.nn as nn
import math
from torch import nn, Tensor
class PositionalEncoder(nn.Module):
def __init__(
self,
dropout: float=0.1,
max_seq_len: int=5000,
d_model: int=512,
batch_first: bool=False
):
"""
Parameters:
dropout: the dropout rate
max_seq_len: the maximum length of the input sequences
d_model: The dimension of the output of sub-layers in the model
(Vaswani et al, 2017)
"""
super().__init__()
self.d_model = d_model
self.dropout = nn.Dropout(p=dropout)
self.batch_first = batch_first
self.x_dim = 1 if batch_first else 0
# copy pasted from PyTorch tutorial
position = torch.arange(max_seq_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(max_seq_len, 1, d_model)
pe[:, 0, 0::2] = torch.sin(position * div_term)
pe[:, 0, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x: Tensor) -> Tensor:
"""
Args:
x: Tensor, shape [batch_size, enc_seq_len, dim_val] or
[enc_seq_len, batch_size, dim_val]
"""
x = x + self.pe[:x.size(self.x_dim)]
return self.dropout(x)트랜스포머는 데이터의 시퀀스를 알지 못하기 때문에 positional encoding으로 전달해주어야 한다. Encoder layer로 들어갈 인풋에 self.pe를 더해주어 시퀀스 정보를 전달하자. 모델에 적용할때는 다음과 같이 파라미터들을 설정한다.
import positional_encoder as pe
# Create positional encoder
self.positional_encoding_layer = pe.PositionalEncoder(
d_model=dim_val,
dropout=dropout_pos_enc,
max_seq_len=max_seq_len
)여기서 dim_val은 input layer의 output dimension이라고 생각하면 된다.
Encoder Layer
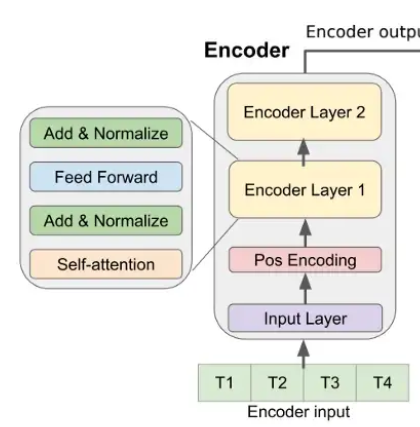
이번에는 Encoder Layer을 구현해보도록 하겠다. 그림에서는 2 층의 encoder layer로 나와있지만 논문에서는 4 encoder layer을 사용한다고 한다. 4개로 구현한다. 트랜스포머 인코드의 경우 파이토치에 이미 구현이 되어있어서 해당 함수를 사용하고자 한다.
encoder_layer = torch.nn.TransformerEncoderLayer(d_model, nhead, batch_first=True)torch.nn.TransformerEncoderLayer에는 위의 그림에서와 같이 self-attention과 feed forward layer가 포함되어있고, Add&Normalize layer도 포함되어있다. 해당 레이어를 4겹 쌓기 위해 다음과 같이 코드를 써준다.
self.encoder = torch.nn.TransformerEncoder(encoder_layer, num_layers=4, norm=None)여기서 norm은 normalization이 포함되어있지 않은 custom encoder layer을 사용할때 지정해주면 된다고 한다. nn.TransformerEncoderlayer는 이미 normalization이 포함되어있다. 전체 모델인 TimeSeriesTransformer 클래스에는 다음과 같이 선언되어 들어간다.
encoder_layer = nn.TransformerEncoderLayer(
d_model=dim_val,
nhead=n_heads,
batch_first=True
)
# Stack the encoder layer n times in nn.TransformerDecoder
self.encoder = nn.TransformerEncoder(
encoder_layer=encoder_layer,
num_layers=n_encoder_layers,
norm=None
)Decoder Input Layer
Decoder Input Layer는 Encoder Input Layer와 같다. nn.Linear()을 이용해서 적용한다.
self.decoder_input_layer = nn.Linear(
in_features=num_predicted_features, # the number of features you want to predict. Usually just 1
out_features=dim_val
)
Decoder Layer
Decoder Layer도 Encoder Layer와 똑같이 만들어준다.
decoder_layer = nn.TransformerDecoderLayer(
d_model=dim_val,
nhead=n_heads,
batch_first=True
)
# Stack the decoder layer n times
self.decoder = nn.TransformerDecoder(
decoder_layer=decoder_layer,
num_layers=n_decoder_layers,
norm=None
)Linear Mapping Layer
이름이 Linear Mapping Layer라 붙었지만 nn.Linear 로 input layer와 구조가 같다. 모델의 최종 아웃풋을 결정하는 레이어이기 때문에 output dim을 정해주어야 한다. out_feature은 target sequencd length와 같도록 설정해준다.
self.linear_mapping = nn.Linear(
in_features=dim_val,
out_features=num_predicted_features
)
전체 모델
import torch.nn as nn
from torch import nn, Tensor
import positional_encoder as pe
import torch.nn.functional as F
class TimeSeriesTransformer(nn.Module):
def __init__(self,
input_size: int,
dec_seq_len: int,
batch_first: bool,
out_seq_len: int=58,
dim_val: int=512,
n_encoder_layers: int=4,
n_decoder_layers: int=4,
n_heads: int=8,
dropout_encoder: float=0.2,
dropout_decoder: float=0.2,
dropout_pos_enc: float=0.1,
dim_feedforward_encoder: int=2048,
dim_feedforward_decoder: int=2048,
num_predicted_features: int=1
):
"""
Args:
input_size: int, number of input variables. 1 if univariate.
dec_seq_len: int, the length of the input sequence fed to the decoder
dim_val: int, aka d_model. All sub-layers in the model produce
outputs of dimension dim_val
n_encoder_layers: int, number of stacked encoder layers in the encoder
n_decoder_layers: int, number of stacked encoder layers in the decoder
n_heads: int, the number of attention heads (aka parallel attention layers)
dropout_encoder: float, the dropout rate of the encoder
dropout_decoder: float, the dropout rate of the decoder
dropout_pos_enc: float, the dropout rate of the positional encoder
dim_feedforward_encoder: int, number of neurons in the linear layer
of the encoder
dim_feedforward_decoder: int, number of neurons in the linear layer
of the decoder
num_predicted_features: int, the number of features you want to predict.
Most of the time, this will be 1 because we're
only forecasting FCR-N prices in DK2, but in
we wanted to also predict FCR-D with the same
model, num_predicted_features should be 2.
"""
super().__init__()
self.dec_seq_len = dec_seq_len
#print("input_size is: {}".format(input_size))
#print("dim_val is: {}".format(dim_val))
# Creating the three linear layers needed for the model
self.encoder_input_layer = nn.Linear(
in_features=input_size,
out_features=dim_val
)
self.decoder_input_layer = nn.Linear(
in_features=num_predicted_features,
out_features=dim_val
)
self.linear_mapping = nn.Linear(
in_features=dim_val,
out_features=num_predicted_features
)
# Create positional encoder
self.positional_encoding_layer = pe.PositionalEncoder(
d_model=dim_val,
dropout=dropout_pos_enc
)
# The encoder layer used in the paper is identical to the one used by
# Vaswani et al (2017) on which the PyTorch module is based.
encoder_layer = nn.TransformerEncoderLayer(
d_model=dim_val,
nhead=n_heads,
dim_feedforward=dim_feedforward_encoder,
dropout=dropout_encoder,
batch_first=batch_first
)
# Stack the encoder layers in nn.TransformerDecoder
# It seems the option of passing a normalization instance is redundant
# in my case, because nn.TransformerEncoderLayer per default normalizes
# after each sub-layer
# (https://github.com/pytorch/pytorch/issues/24930).
self.encoder = nn.TransformerEncoder(
encoder_layer=encoder_layer,
num_layers=n_encoder_layers,
norm=None
)
decoder_layer = nn.TransformerDecoderLayer(
d_model=dim_val,
nhead=n_heads,
dim_feedforward=dim_feedforward_decoder,
dropout=dropout_decoder,
batch_first=batch_first
)
# Stack the decoder layers in nn.TransformerDecoder
# It seems the option of passing a normalization instance is redundant
# in my case, because nn.TransformerDecoderLayer per default normalizes
# after each sub-layer
# (https://github.com/pytorch/pytorch/issues/24930).
self.decoder = nn.TransformerDecoder(
decoder_layer=decoder_layer,
num_layers=n_decoder_layers,
norm=None
)
def forward(self, src: Tensor, tgt: Tensor, src_mask: Tensor=None,
tgt_mask: Tensor=None) -> Tensor:
"""
Returns a tensor of shape:
[target_sequence_length, batch_size, num_predicted_features]
Args:
src: the encoder's output sequence. Shape: (S,E) for unbatched input,
(S, N, E) if batch_first=False or (N, S, E) if
batch_first=True, where S is the source sequence length,
N is the batch size, and E is the number of features (1 if univariate)
tgt: the sequence to the decoder. Shape: (T,E) for unbatched input,
(T, N, E)(T,N,E) if batch_first=False or (N, T, E) if
batch_first=True, where T is the target sequence length,
N is the batch size, and E is the number of features (1 if univariate)
src_mask: the mask for the src sequence to prevent the model from
using data points from the target sequence
tgt_mask: the mask for the tgt sequence to prevent the model from
using data points from the target sequence
"""
#print("From model.forward(): Size of src as given to forward(): {}".format(src.size()))
#print("From model.forward(): tgt size = {}".format(tgt.size()))
# Pass throguh the input layer right before the encoder
src = self.encoder_input_layer(src) # src shape: [batch_size, src length, dim_val] regardless of number of input features
#print("From model.forward(): Size of src after input layer: {}".format(src.size()))
# Pass through the positional encoding layer
src = self.positional_encoding_layer(src) # src shape: [batch_size, src length, dim_val] regardless of number of input features
#print("From model.forward(): Size of src after pos_enc layer: {}".format(src.size()))
# Pass through all the stacked encoder layers in the encoder
# Masking is only needed in the encoder if input sequences are padded
# which they are not in this time series use case, because all my
# input sequences are naturally of the same length.
# (https://github.com/huggingface/transformers/issues/4083)
src = self.encoder( # src shape: [batch_size, enc_seq_len, dim_val]
src=src
)
#print("From model.forward(): Size of src after encoder: {}".format(src.size()))
# Pass decoder input through decoder input layer
decoder_output = self.decoder_input_layer(tgt) # src shape: [target sequence length, batch_size, dim_val] regardless of number of input features
#print("From model.forward(): Size of decoder_output after linear decoder layer: {}".format(decoder_output.size()))
#if src_mask is not None:
#print("From model.forward(): Size of src_mask: {}".format(src_mask.size()))
#if tgt_mask is not None:
#print("From model.forward(): Size of tgt_mask: {}".format(tgt_mask.size()))
# Pass throguh decoder - output shape: [batch_size, target seq len, dim_val]
decoder_output = self.decoder(
tgt=decoder_output,
memory=src,
tgt_mask=tgt_mask,
memory_mask=src_mask
)
#print("From model.forward(): decoder_output shape after decoder: {}".format(decoder_output.shape))
# Pass through linear mapping
decoder_output = self.linear_mapping(decoder_output) # shape [batch_size, target seq len]
#print("From model.forward(): decoder_output size after linear_mapping = {}".format(decoder_output.size()))
return decoder_outputInitializing Transformer Model
## Model parameters
dim_val = 512 # This can be any value divisible by n_heads. 512 is used in the original transformer paper.
n_heads = 8 # The number of attention heads (aka parallel attention layers). dim_val must be divisible by this number
n_decoder_layers = 4 # Number of times the decoder layer is stacked in the decoder
n_encoder_layers = 4 # Number of times the encoder layer is stacked in the encoder
input_size = 1 # The number of input variables. 1 if univariate forecasting.
dec_seq_len = 92 # length of input given to decoder. Can have any integer value.
enc_seq_len = 153 # length of input given to encoder. Can have any integer value.
output_sequence_length = 58 # Length of the target sequence, i.e. how many time steps should your forecast cover
max_seq_len = enc_seq_len # What's the longest sequence the model will encounter? Used to make the positional encoder
model = tst.TimeSeriesTransformer(
dim_val=dim_val,
input_size=input_size,
dec_seq_len=dec_seq_len,
max_seq_len=max_seq_len,
out_seq_len=output_sequence_length,
n_decoder_layers=n_decoder_layers,
n_encoder_layers=n_encoder_layers,
n_heads=n_heads)모델의 파라미터를 설정해주기 위해 위와 같이 선언해준다.
Transformer Model의 input data를 만드는 방법
위의 모델 구현에서 볼 수 있듯, forward에는 4개의 argument가 들어간다. src, trg, src_mask, trg_mask. 데이터를 어떻게 다루어야 할지 알아보자.
먼저 src는 source의 줄임말으로, 본인이 가지고 있는 데이터 (ex. 한달치 날씨 데이터) 에서 학습에 사용할 원하는 만큼의 부분적인 데이터 시퀀스 (ex. 5일치 날씨 데이터)를 말한다. src 시퀀스의 길이는 이 모델로 날씨를 예측할때, 이전 날씨를 얼마나 볼 것인지(ex. 직전 5일치의 날씨 데이터를 바탕으로 regression 하게 된다)를 정한다.
trg은 target의 줄임말으로, 디코더의 인풋으로 들어가게 된다. 여기서 target은 ground-truth를 의미하는 것은 아니고, src의 마지막 data point와, 마지막 data point를 제외한 actual target sequence의 모든 data point 시퀀스를 의미한다. trg의 length는 actual target sequence와 같아야 한다.
예를 한번 들어보자. 10개의 이전 데이터로부터 4개의 미래 데이터를 예측하고자 한다면, Encoder Input에는 (x1, x2, ..., x10)이, decoder input에는 (x10, ..., x13)이, 그리고 decoder output으로는 (x11, ..., x14)가 될 것이다. src와 trg을 return해주는 함수는 다음과 같이 구현할 수 있다. get_src_trg에 들어가는 sequence의 경우 전체 데이터셋의 sub-sequence로, 길이는 input_sequence_length + target_seqence_length이다.
def get_src_trg(
self,
sequence: torch.Tensor,
enc_seq_len: int,
target_seq_len: int
) -> Tuple[torch.tensor, torch.tensor, torch.tensor]:
"""
Generate the src (encoder input), trg (decoder input) and trg_y (the target)
sequences from a sequence.
Args:
sequence: tensor, a 1D tensor of length n where
n = encoder input length + target sequence length
enc_seq_len: int, the desired length of the input to the transformer encoder
target_seq_len: int, the desired length of the target sequence (the
one against which the model output is compared)
Return:
src: tensor, 1D, used as input to the transformer model
trg: tensor, 1D, used as input to the transformer model
trg_y: tensor, 1D, the target sequence against which the model output
is compared when computing loss.
"""
#print("Called dataset.TransformerDataset.get_src_trg")
assert len(sequence) == enc_seq_len + target_seq_len, "Sequence length does not equal (input length + target length)"
#print("From data.TransformerDataset.get_src_trg: sequence shape: {}".format(sequence.shape))
# encoder input
src = sequence[:enc_seq_len]
# decoder input. As per the paper, it must have the same dimension as the
# target sequence, and it must contain the last value of src, and all
# values of trg_y except the last (i.e. it must be shifted right by 1)
trg = sequence[enc_seq_len-1:len(sequence)-1]
#print("From data.TransformerDataset.get_src_trg: trg shape before slice: {}".format(trg.shape))
trg = trg[:, 0]
#print("From data.TransformerDataset.get_src_trg: trg shape after slice: {}".format(trg.shape))
if len(trg.shape) == 1:
trg = trg.unsqueeze(-1)
#print("From data.TransformerDataset.get_src_trg: trg shape after unsqueeze: {}".format(trg.shape))
assert len(trg) == target_seq_len, "Length of trg does not match target sequence length"
# The target sequence against which the model output will be compared to compute loss
trg_y = sequence[-target_seq_len:]
#print("From data.TransformerDataset.get_src_trg: trg_y shape before slice: {}".format(trg_y.shape))
# We only want trg_y to consist of the target variable not any potential exogenous variables
trg_y = trg_y[:, 0]
#print("From data.TransformerDataset.get_src_trg: trg_y shape after slice: {}".format(trg_y.shape))
assert len(trg_y) == target_seq_len, "Length of trg_y does not match target sequence length"
return src, trg, trg_y.squeeze(-1) # change size from [batch_size, target_seq_len, num_features] to [batch_size, target_seq_len]Decoder Input Masking
src_mask와 trg_mask를 구현하기에 앞서, 트랜스포머에서 자주 사용하는 2가지의 masking 방법을 알아보자.
1. Padding Masking: 길이가 다른 seqence 데이터들을 사용할때, max_seqence length보다 작은 데이터들을 padding token을 이용해서 빈 부분들을 채워준다.
2. Decoder Input Masking(look ahead masking): future token의 정보에 접근하지 못하도록 마스킹해준다.
본 예제에서는 모두 동일한 시퀀스 길이를 가지는 데이터셋을 이용하기 때문에 2번을 사용하도록 한다. 디코더는 2개의 input을 가지고 있다. 인코더의 output과, 디코더 input. 둘 다 masking이 필요하다. src_mask는 encoder output을 masking 한것으로 shape은 [target sequence length, encoder sequence length] 이다. trg_mask는 decoder input을 masking 한 것으로, shape은 [target sequence length, target sequence length] 이다.
def generate_square_subsequent_mask(dim1: int, dim2: int) -> Tensor:
"""
Generates an upper-triangular matrix of -inf, with zeros on diag.
Source:
https://pytorch.org/tutorials/beginner/transformer_tutorial.html
Args:
dim1: int, for both src and tgt masking, this must be target sequence
length
dim2: int, for src masking this must be encoder sequence length (i.e.
the length of the input sequence to the model),
and for tgt masking, this must be target sequence length
Return:
A Tensor of shape [dim1, dim2]
"""
return torch.triu(torch.ones(dim1, dim2) * float('-inf'), diagonal=1)
# Input length
enc_seq_len = 100
# Output length
output_sequence_length = 58
# Make src mask for decoder with size:
tgt_mask = utils.generate_square_subsequent_mask(
dim1=output_sequence_length,
dim2=output_sequence_length
)
src_mask = utils.generate_square_subsequent_mask(
dim1=output_sequence_length,
dim2=enc_seq_len
)
'컴퓨터공학' 카테고리의 다른 글
| [해결법] 이동할 수 없는 파일이 있는 지점을 벗어나 볼륨을 축소할 수 없습니다 (0) | 2023.09.12 |
|---|---|
| vscode 오류, 프로세스에서 없는 파이프에 쓰려고 했습니다 해결법 (0) | 2023.03.20 |
| 리눅스에 CMake 설치하기 (0) | 2022.12.20 |
| 파이토치 부분 pretrained 모델 쉽게 만들기 (0) | 2022.12.10 |
| Perceiver IO: Optical Flow (0) | 2022.07.10 |
