
detection 공부를 해보려한다. 21년도 서베이 페이퍼를 하나 읽고, 22년도부터 나온 신상 모델들은 하나하나 논문 읽고 코드 분석해보면서 읽어보도록 하겠다. 오늘 리뷰할 논문 제목은 아래와 같다.
참고 논문 : A survey of modern deep learning based object detection models
A survey of modern deep learning based object detection models
Object Detection is the task of classification and localization of objects in an image or video. It has gained prominence in recent years due to its w…
www.sciencedirect.com
Introduction
Object detection은 이미지나 비디오에서의 물체를 classification/localization 하는 분야이다. 초기 detection 모델들은 hand-crafted feature extractor를 사용해서 새로운 데이터에 대한 강건함이 떨어졌었다. CNN이 이미지넷에서 큰 성공을 보여주고 나서 detection 분야에도 딥러닝 기반 방법론들이 많이 쓰이게 되었는데, 요즘에는 자율주행뿐 아니라 보안/의료 쪽에도 많이 쓰인다고 한다.
Background
Object detection은 간단하게 보면 물체를 인식만 하는 classification 테스크를 확장한 것인데, predefined classes에 해당하는 모든 물체들을 감지하고, 그 위치를 박스형태로 나타내준다. 일반적으로 지도학습으로 이루어진다.
Object detection이 직면하고 있는 문제들은 다음과 같다.
- Intra class variation: occlusion, illumination, pose, viewpoint 등의 이유로 클래스 추정에 변동이 생기는 경우
- Numer of categories: 분류할 수 있는 클래스 수가 많아서 더 정교한 데이터를 필요로 하나 사실 그게 더 어려움
- Efficiency: 모바일기기에서도 사용할 수 있을만한 모델이 좋지
Dataset & Metrics
자주쓰는 데이터셋: PASCAL VOC 07/12, ILSVRC, MS-COCO, Google open-image
-> 클래스 별로 이미지 수에 차이가 있어 bias 우려
Metric의 경우 mean Average Precision(mAP)가 최종 모델 성능 평가에 가장 많이 쓰인다. mAP는 모든 클래스의 average precision의 평균을 의미하며, 여기서 precision은 예측한 것 중 맞는 비율로, 수식은 다음과 같다.

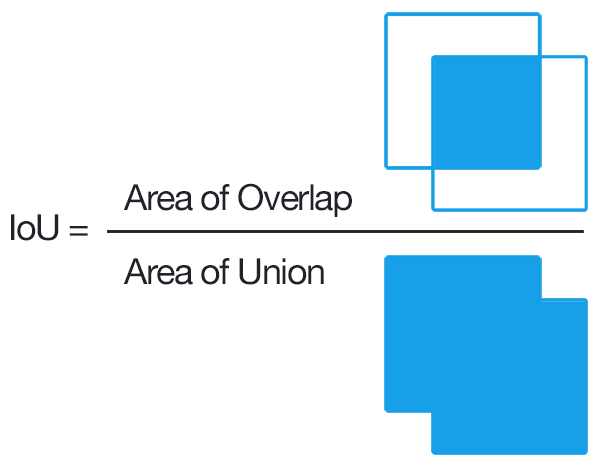
True Positive, False Positive .. 의 개념을 알기전에 IoU부터 짚고 넘어가도록 하겠다. IoU란 Intersection over Union의 약자로, ground truth와 predicted bounding box가 얼마나 일치하는지를 알려준다. IoU가 threshold보다 크면 잘 예측한 것이므로 True Positive라 하고, 작으면 False Positive라 한다. IoU는 다음과 같이 계산한다.
Precision/Recall 관련하여 잘 소개되어 있는 블로그가 있어 링크를 첨부한다
https://driip.me/cc48042b-a3fa-4aa8-b559-383d9806baba
Object Detection에서의 Precision, Recall
Precision, Recall 개념을 Object Detection에 적용하여 알아보자. 궁극적으로는 mAP를 이해하기 위해 필요하다.
driip.me
Object Detectors
본 챕터에서는 two-stage/single-stage 두가지로 나누어 설명한다.
Two-stage detector
step 1: object proposal
step 2: classify & localize
단점: 모델이 복잡하고 global context가 부족하며 proposal에 시간이 많이 소요된다.
Single-stage detector
dense sampling을 통한 single-shot clasify & localize
장점: two-stage detector보다 real-time 성능이 좋고 디자인이 단순하다.
Two-stage detector
R-CNN
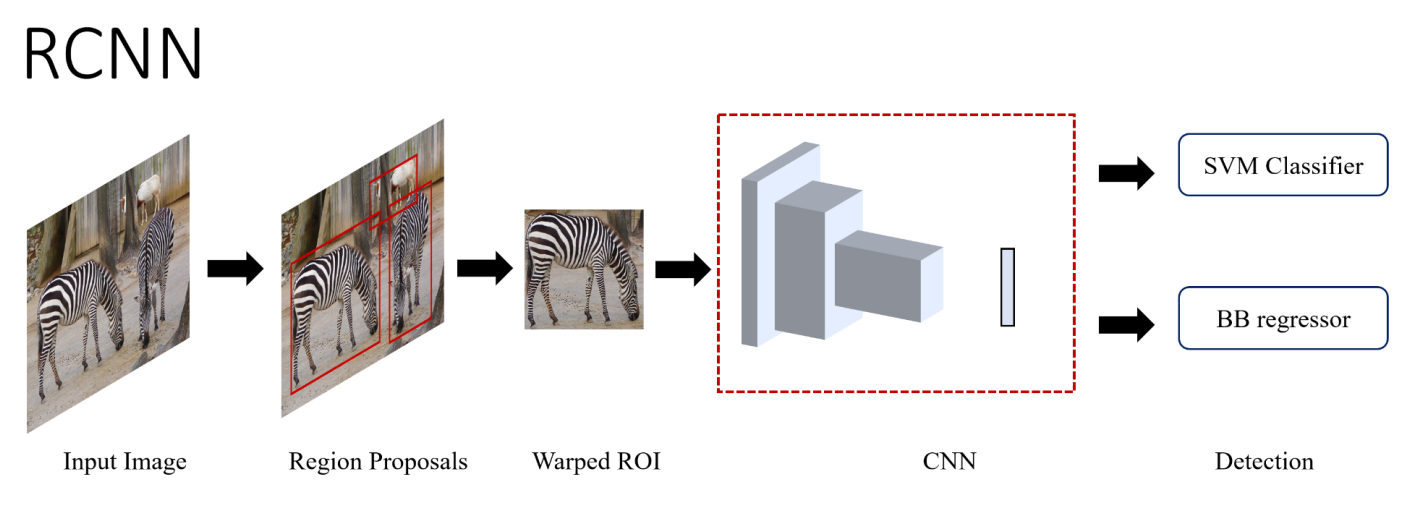
- region proposal module로 2000개의 object candidate 추출, Selective Search 기반으로 물체가 있을법한 곳을 찾음
- 적당한 사이즈로 warp + CNN (pretrained with a large classification dataset)
- 4096-dimension feature vector를 Support Vector Machine을 이용하여 confidence score을 계산
- Non-maximum suppression
- bounding box regressor을 통한 bounding box 추정

SPP-Net

앞의 R-CNN의 경우 CNN의 output을 맞춰주기 위해 input을 warping을 통해 고정했다. 하지만 이런 방식은 객체 인식에서의 정확도를 떨어뜨리며, SPP-Net에서는 spatial pyramid pooling을 이용해서 해결한다.
- fc 레이어 때문에 입력 사이즈를 고정해주었던 것
- region proposal module 전에 CNN을 돌리고, pooling layer 추가
- 이렇게 함으로써 다양한 크기의 입력 이미지에 대응 가능

위의 그림에서 윗 라인이 RCNN을 나타내고, 밑에가 SPP-Net이다.
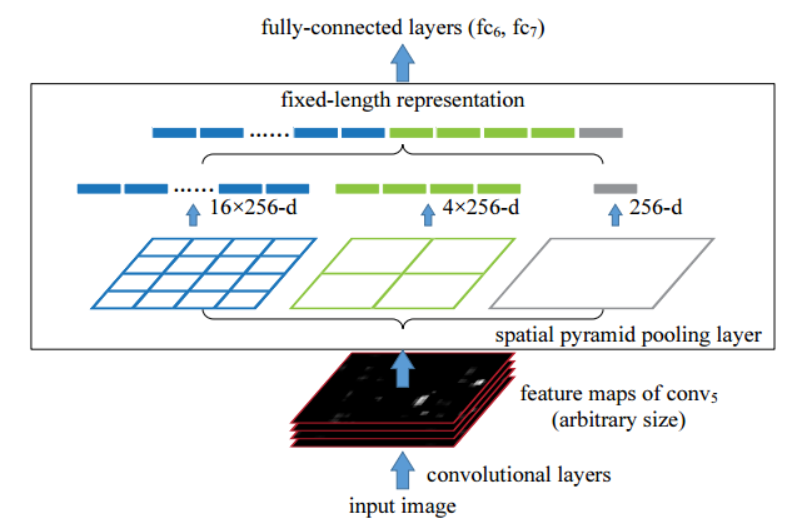
위와 같이 feature map에서 여러 사이즈의 pooling layer을 추가하여 마지막 fc layer에 들어갈 length를 맞춘다.
- Non-maximum suppression
- bounding box regressor을 통한 bounding box 추정
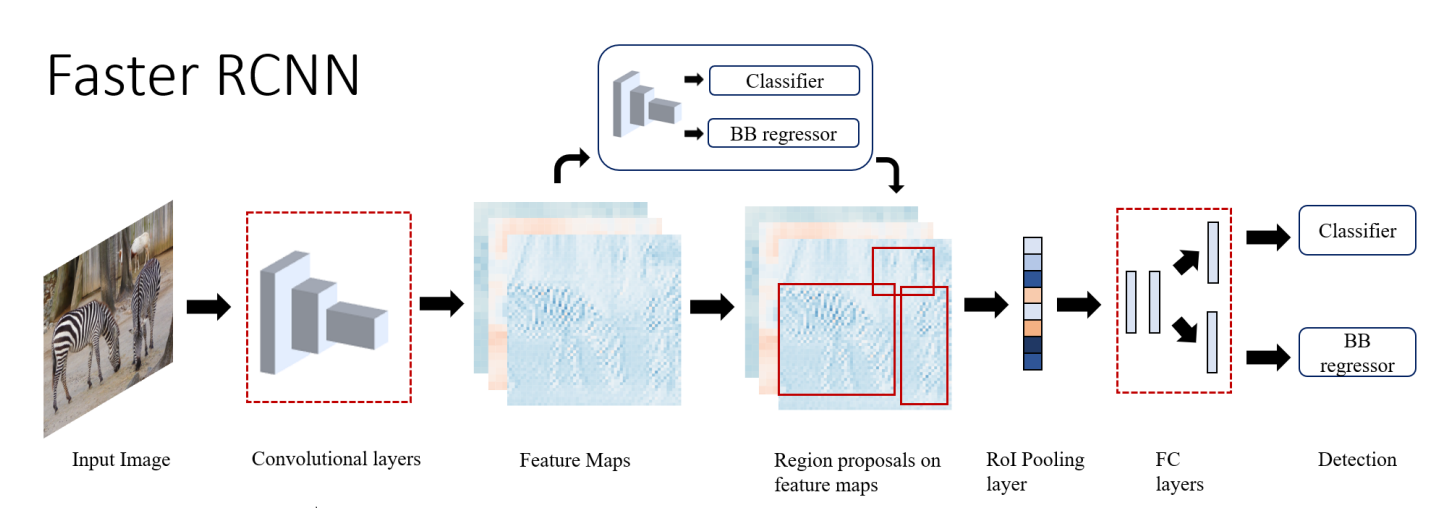
Fast R-CNN
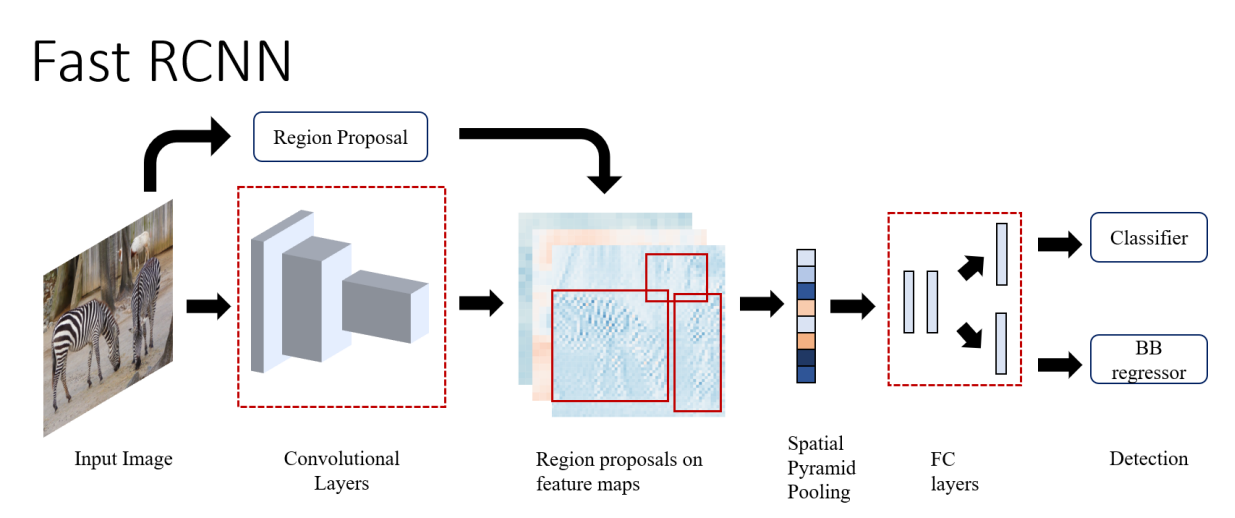
위의 것들은 모두 각 모듈들을 따로 따로 학습을 해줘야 하는 단점이 있었음. Fast R-CNN에서는 single end-to-end 모델을 제시한다.
- Selective Search를 통해 RoI 구하기
- 이미지를 CNN에 넣어서 feature map을 추출
- 위에서 찾은 RoI를 feature map에 프로젝션 시킴
- RoI Pooling (SPP-Net 에서의 spatial pyramid pooling 역할)
- FC + softmax / FC + bounding box regressor로 각각 class와 localization 수행
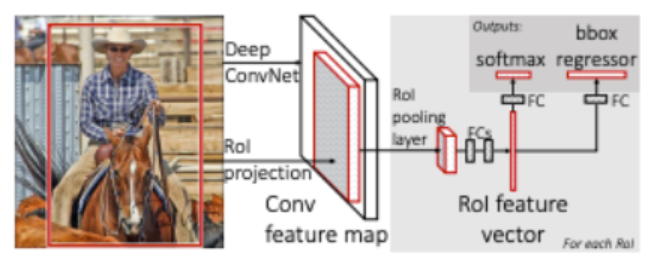
Faster R-CNN
Fast R-CNN이 빠르긴했으나 Region proposal쪽이 여전히 느렸음. Faster R-CNN은 CNN 기반의 Region proposal network을 제시한다. 다양한 object 사이즈에 대응하기 위해 Anchor box를 사전에 지정한다.
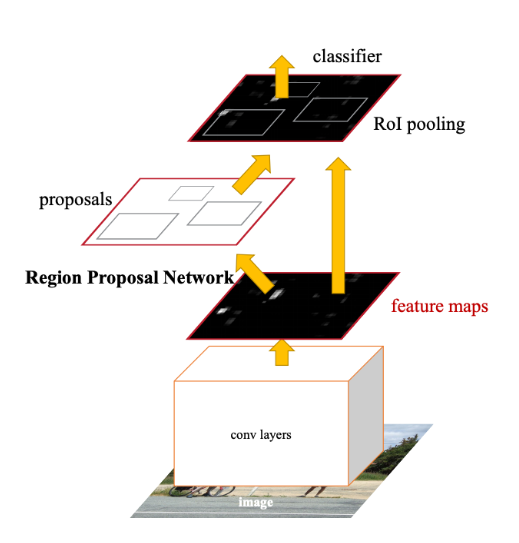
- pre-trained된 CNN 모델에 이미지를 넣어 feature map을 뽑는다.
- feature map에 RPN을 사용하여 proposal을 얻는다.
- region proposal을 feature map에 다시 맵핑시켜 RoI pooling을 수행
- FC layer을 통해 Classification과 Bounding box regression을 수행
FPN

이미지에서 feature을 뽑아내는 방법에 대한 고찰을 한다. 기존의 방법은 다음과 같이 3가지 (a, b, c) 가 있다.

(a) 이미지 자체를 resize 하며 각 level의 이미지에서 feature을 뽑는 경우. 연산량이 많아 느리다. 2000대 이전에 쓰였던 가장 기본적인 방식
(b) Single image input에서 CNN을 거쳐 feature 뽑기. ConvNet은 크기변화에 강인하다. 하지만 정확도가 부족했음. Fast/Faster R-CNN, SPPNet이 이 방식을 사용했는데, (a) 방식이 multi-scale feature representation을 사용함으로써 모든 레벨의 semantic 정보들이 유용하다는걸 알지만, inference 시간이 너무오래걸림.
(c) (a)와 같이 image pyramid를 사용하는것 외에 multi-scale을 고려할 방법이 없을까? 해서 나온게 (c)이다. CNN기반 각 레이어를 통과한 feature map을 image pyramid처럼 이용하는 것. Single Shot Detector (SSD)가 해당 방식을 이용한 첫 시도이다. 하지만 이런 방식에서의 high resolution feature map은 low resolution feature을 가지고 있지 못한다.
(d) FPN에서 제안하는 Feature Pyramid Network는 top-down architecture을 이용해서 해당 level의 feature와 low-level feature을 합쳐준다. 이렇게 함으로써 모든 scale에 대해 high-level semantic을 보장할 수 있고, 정확도도 향상됨. Faster R-CNN의 RPN 대신에 사용한다.
R-FCN
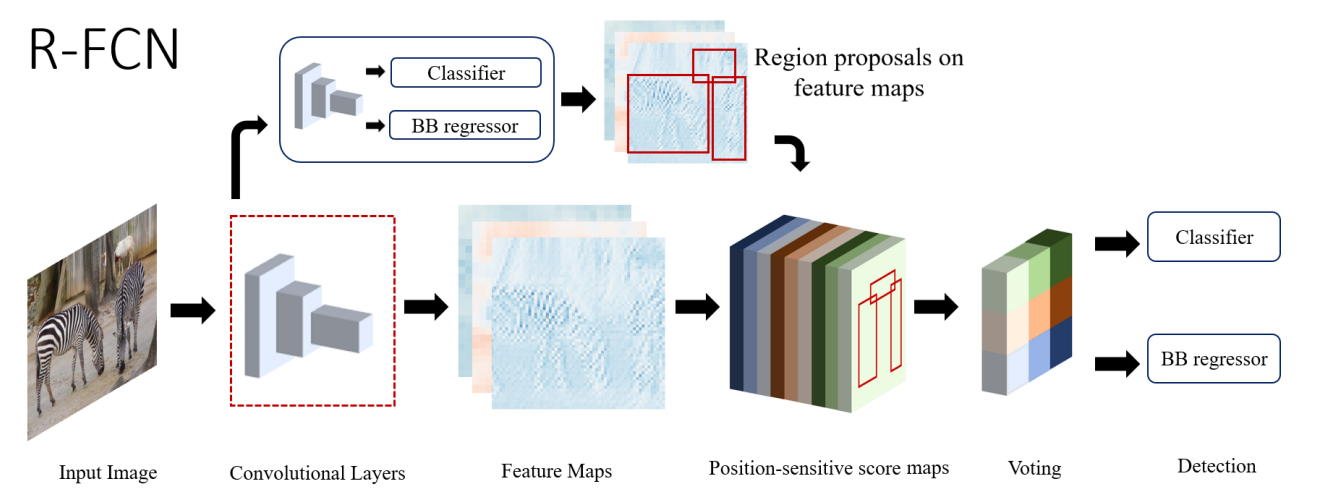
모델의 앞부분에 사용되는 deep CNN layer는 translation-invariant 하기 때문에 classification에는 도움이 되지만 localization에 안좋은 영향을 끼친다. 이 문제를 position-sensitiv score map을 통해 해결함. 이 score map은 물체의 상대적인 위치를 encode하고 나중에 해당 정보를 합쳐줌으로써 localization 성능을 향상한다. R-FCN은 RoI를 k x k 그리드로 나누고 각 cell과 detection class feature map과의 likeliness를 계산하여 점수를 매긴다. 이 점수는 나중에 클래스를 추정하는 것에 사용된다.
계속 추가됩니다. . .
'컴퓨터공학 > AI' 카테고리의 다른 글
| [논문 리뷰] A Comprehensive Survey on Multimodal Retrieval-Augmented Generation (0) | 2025.08.31 |
|---|---|
| Accelerating Stochastic Gradient Descent using Predictive Variance Reduction (0) | 2023.06.25 |
| Adam: A method for stochastic optimization (0) | 2023.06.24 |
| SingSGD (0) | 2023.06.23 |
| A decision-theoretic generalization of on-line learning and an application to boosting (0) | 2023.06.17 |
