
오늘은 실제 학습시에 사용하는 소프트웨어들에 대해 알아봅니다. 그전에 cpu와 gpu가 뭔지부터 알아보자.
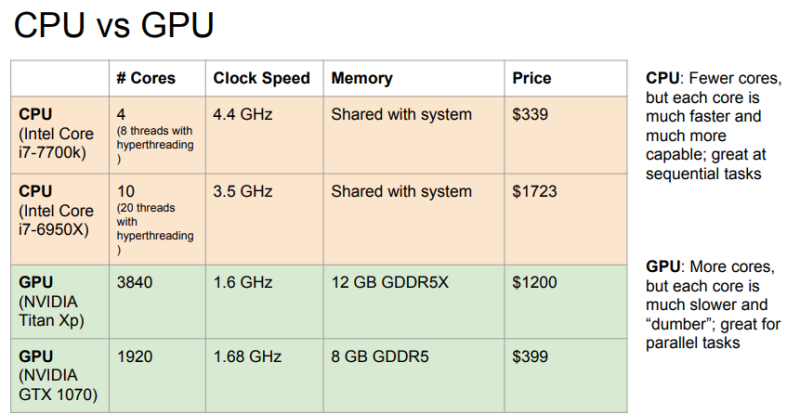
먼저 CPU, central processing unit은 GPU에 비해 비교적 작은 사이즈로 제작이 되고, 램에서 메모리를 가져다가 사용한다. GPU(Graphics processing unit)의 경우 쿨러도 따로있고 파워도 많이 먹는다. gpu의 병렬연산이 행렬곱 연산에 최적화되어 있기 때문에 딥러닝 연산에 사용되고 있고, 딥러닝은 엔비디아가 거의 독점하고 있다.
CUDA를 이용해서 gpu에서 실행되는 코드를 직접 작성할 수 있으나 상당히 어려운 일이다. 우리는 그냥 라이브러리 쓰면되고, 딥러닝을 위해 CUDA를 직접작성하는 일은 없을 것이다.
어쨋든 GPU programming 언어는 다음과 같은 것들이 있다.
- CUDA
- OpenCK
- Udacity
GPU로 학습을 할 때 문제
- Model과 가중치는 GPU 램에 상주하고 있지만 실제 train data는 하드드라이브에 있음
- 따라서 train time에 디스크에서 데이터를 잘 읽어와야 됨 아니면 보틀넥일어남
- gpu는 forward/backward가 빠르지만 디스크에서 데이터 읽어들이는 것이 보틀넥
해결책
- 데이터 작으면 그냥 ram에 올려놓기
- HDD말고 SDD 써서 데이터 읽는 속도 개선
- CPU 다중스레드 이용해서 데이터를 ram에 미리 올려놔(pre fetching) 그리고 버퍼에서 gpu로 데이터 전송시키면 성능좋아짐
Q. 데이터 읽을 때 병목 해결을 위해서 우리가 할 수 있는 것?
- CPU에서 미리 불러오는 것 (pre-fetching)
- gpu가 계산하는 동안 cpu 백그라운드 스레드가 디스크에서 데이터 불러옴
- 어짜피 딥러닝 프레임워크에 다 구현되어 있음 걱정 ㄴ
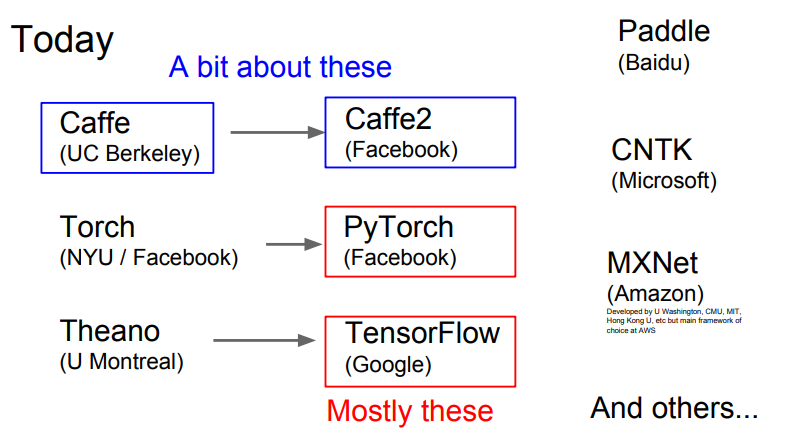
요즘 이용하는 딥러닝 프레임워크들은 아래와 같은 것들이 있고, 이 수업에서는 네모친것들만 다뤄보겠습니다.
그전에, 먼저 딥러닝 프레임워크를 사용하는 이유?
1. 그래프를 직접 만들지 않아도 된다.
2. forward pass 만 잘 구현해 놓으면 back propagation은 알아서 구성됨
3. GPU를 효율적으로 사용할 수 있다.
tips
- numpy는 gpu에서 돌아가지 않는다.
TensorFlow
텐서플로우 사용은 크게 두단계로 나누어진다.

1. 빨간색 박스 computational graph 정의
2. 그래프 실행
이부분은 코드 주석으로 설명을 다는 것이 편할것 같다.
import numpy as np
import tensorflow as tf
N,D,H= 64,1000,100
# 그래프의 입력노드 생성, 메모리할당은 일어나지 않는다.
x=tf.placeholder(tf.float32,shape=(N,D))
y=tf.placeholder(tf.float32,shape=(N,D))
w1=tf.placeholder(tf.float32,shape=(D,H))
w2=tf.placeholder(tf.float32,shape=(H,D))
# x와 w1 행렬곱 연산 후 maximum을 통한 ReLU 구현
h=tf.maximum(tf.matmul(x,w1),0)
y_pred=tf.matmul(h,w2)
diff=y_pred-y
# L2 Euclidean
loss=tf.reduce_mean(tf.reduce_sum(diff**2,axis=1))
# loss 계산, gradient 계산. backprop 직접구현이 필요없다
grad_w1,grad_w2=tf.gradients(loss,[w1,w2])
# 아직까지 실제 계산이 이루어지지는 않았다.
# Tensorflow session : 실제 그래프를 실행
with tf.Session() as sess:
# 그래프에 들어갈 value 지정. tensorflow는 numpy를 지원한다.
values={x:np.random.randn(N,D),
w1: np.random.randn(D,H),
w2:np.random.randn(H,D),
y:np.random.randn(N,D),}
# 실제 그래프 실행. 출력으로 loss와 gradient
# feed_dict로 실제 값 전달해주기
# 출력 값은 numpy array
out=sess.run([loss,grad_w1,grad_w2],feed_dict=values)
loss_val, grad_w1_val,grad_w2_val=out- forward pass에서 그래프가 실행될 때마다 가중치를 넣어주어야 한다.
- GPU/CPU간의 데이터 교환은 엄청 느리고 비용도 크다
N,D,H= 64,1000,100
# 그래프의 입력노드 생성, 메모리할당은 일어나지 않는다.
x=tf.placeholder(tf.float32,shape=(N,D))
y=tf.placeholder(tf.float32,shape=(N,D))
# variables로 변경. tf.random_normal로 초기화 설정
w1=tf.Variable(tf.random_normal((D,H)))
w2=tf.Variable(tf.random_normal((H,D)))
# x와 w1 행렬곱 연산 후 maximum을 통한 ReLU 구현
h=tf.maximum(tf.matmul(x,w1),0)
y_pred=tf.matmul(h,w2)
diff=y_pred-y
# L2 Euclidean
loss=tf.reduce_mean(tf.reduce_sum(diff**2,axis=1))
# loss 계산, gradient 계산. backprop 직접구현이 필요없다
grad_w1,grad_w2=tf.gradients(loss,[w1,w2])
# assign 함수를 통해 그래프 내에서 업뎃이 일어날 수 있도록 해줌
learning_rate=1e-5
new_w1=w1.assign(w1-learning_rate* grad_w1)
new_w2=w2.assign(w2-learning_rate* grad_w2)
# w1와 w2를 업뎃하라고 명시적으로 넣어주어야 한다.
# tensorflow는 output에 필요한 연산만 수행한다.
# new_w1, new_w2를 직접적으로 넣어줄 수 있으나, 사이즈가 큰 tensor의 경우
# tensorflow가 출력을 하는 것은 cpu/gpu간 데이터 전송이 필요하므로 좋지 않다
# 따라서 dummy node인 updates를 만들어 그래프에 추가
updates=tf.group(new_w1,new_w2)
# 아직까지 실제 계산이 이루어지지는 않았다.
# Tensorflow session: 실제 그래프를 실행
with tf.Session() as sess:
# 그래프 내부 변수들 초기화
sess.run(tf.global_variables_initializer())
values={x:np.random.randn(N,D),
y:np.random.randn(N,D),}
for t in range(50):
loss_val=sess.run([loss,updates],feed_dict=values)tf.contrib.layer 라이브러리 사용
N,D,H= 64,1000,100
# 그래프의 입력노드 생성, 메모리할당은 일어나지 않는다.
x=tf.placeholder(tf.float32,shape=(N,D))
y=tf.placeholder(tf.float32,shape=(N,D))
# Xavier로 초기화
init=tf.contrib.layers.xavier_initializer()
# 내부적으로 w1, b2를 변수로 만들어주고 초기화
h=tf.layers.dense(inputs=x,units=H,activation=tf.nn.relu,kernel_initializer=init)
y_pred=tf.layers.dense(inputs=h,units=D,kernel_initializer=init)
# tensorflow 내장함수로 변경가능
loss=tf.losses.mean_squared_error(y_pred,y)
# optimizer을 이용해서 gradient를 계산하고 가중치를 업뎃할 수 있다
optimizer=tf.train.GradientDescentOptimizer(1e-5)
updates=optimizer.minimize(loss)
# 아직까지 실제 계산이 이루어지지는 않았다.
# Tensorflow session: 실제 그래프를 실행
with tf.Session() as sess:
# 그래프 내부 변수들 초기화
sess.run(tf.global_variables_initializer())
values={x:np.random.randn(N,D),
y:np.random.randn(N,D),}
for t in range(50):
loss_val=sess.run([loss,updates],feed_dict=values)tensorflow기반 high level wrapper들에는 다음과 같은 것들이 있다.
Keras (https://keras.io/)
TFLearn (http://tflearn.org/)
TensorLayer (http://tensorlayer.readthedocs.io/en/latest/)
tf.layers (https://www.tensorflow.org/api_docs/python/tf/layers)
TF-Slim (https://github.com/tensorflow/models/tree/master/inception/inception/slim)
tf.contrib.learn (https://www.tensorflow.org/get_started/tflearn)
Pretty Tensor (https://github.com/google/prettytensor)
Pytorch(페이스북)
3가지 주요 요소
1. tensor: imperative array, gpu에서 돌아감
2. variable: 그래프의 노드. 그래프 구성 및 그레디언트 계산
3. module: NN 구성
파이토치는 고수준의 추상화를 이미 내장하고 있다. 코드를 보자
import torch
from torch.autograd import Variable
# GPU에서 돌아가도록 데이터 타입을 변경
dtype=torch.cuda.FloatTensor
N,D_in,H,D_out=64,1000,100,10
# 가중치에 대한 gradient만 True로 변경한다
x=Variable(torch.randn(N,D_in),requires_grad=False)
y=Variable(torch.randn(N,D_out),requires_grad=False)
w1=Variable(torch.randn(D_in,H),requires_grad=True)
w2=Variable(torch.randn(H,D_out),requires_grad=True)
#학습률 설정
learning_rate=1e-6
for t in range(500):
y_pred=x.mm(w1).clamp(min=0).mm(w2)
loss=(y_pred-y).pow(2).sum()
if w1.grad:w1.grad.data.zero_()
if w2.grad:w2.grad.data.zero_()
loss.backward()
w1.data-=learning_rate* w1.grad.data
w2.data-=learning_rate* w2.grad.datax.data 는 tensor
x.grad 는 variable of gradients, x.data와 데이터타입 같다
x.grad.data는 Tensor of gradient
higher-level wrapper로는 nn이 있다
텐서플로우처럼 종류가 많지는 않지만 하나로도 쓸만하다
import torch
from torch.autograd import Variable
# GPU에서 돌아가도록 데이터 타입을 변경
dtype=torch.cuda.FloatTensor
N,D_in,H,D_out=64,1000,100,10
x=Variable(torch.randn(N,D_in))
y=Variable(torch.randn(N,D_out),requires_grad=False)
# Define our model as a sequence of layers
model =torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H,D_out))
# common loss functions도 제공한다
loss_fn=torch.MSELoss(size_average=False)
#학습률 설정
learning_rate=1e-4
for t in range(500):
# model에 x 넣고 prediction
y_pred=model(x)
loss=loss_fn(y_pred,y)
#backward pass, gradient 계산
model.zero_grad()
loss.backward()
for param in model.parameters():
param.data-=learning_rate*param.grad.dataoptimizer 사용
import torch
from torch.autograd import Variable
# GPU에서 돌아가도록 데이터 타입을 변경
dtype=torch.cuda.FloatTensor
N,D_in,H,D_out=64,1000,100,10
x=Variable(torch.randn(N,D_in))
y=Variable(torch.randn(N,D_out),requires_grad=False)
# Define our model as a sequence of layers
model =torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H,D_out))
# common loss functions도 제공한다
loss_fn=torch.MSELoss(size_average=False)
#학습률 설정
learning_rate=1e-4
# Use optimizer for different update rules
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate)
for t in range(500):
# model에 x 넣고 prediction
y_pred=model(x)
loss=loss_fn(y_pred,y)
#backward pass, gradient 계산
optimizer.zero_grad()
loss.backward()
# 그레디언트 계산 후 모든 파라미터 업뎃
optimizer.step()define your own Modules using autograd!
import torch
from torch.autograd import Variable
from torch.utils.data import TensorDatasetm DataLoader
# 단일 모듈로 model 생성
# backward는 autograd가 알아서 해줌
class TwoLayerNet(torch.nn.Module):
def __init__(self, D_in, H, D_out):
super(TwoLayerNet, self).__init__()
self.linear1=torch.nn.Linear(D_in,H)
self.linear2=torch.nn.Linear(H,D_out)
def forward(self,x):
h_relu=self.linear1(x).clamp(min=0)
y_pred=self.linear2(h_relu)
return y_pred
N,D_in,H,D_out=64,1000,100,10
x=Variable(torch.randn(N,D_in))
y=Variable(torch.randn(N,D_out),requires_grad=False)
# DataLoader가 minibatching, shuffling, multithreading 관리
loader=DataLoader(TensorDataset(x,y).batch_size=8)
model = TwoLayerNet(D_in, H, D_out)
criterion=torch.nn.MSELoss(size_average=False)
optimizer=torch.optim.Adam(model.parameters(),lr=1e-4)
for epoch in range(10):
for x_batch, y_batch in loader:
# model에 x 넣고 prediction
x_var, y_var=Variable(x),Variable(y)
y_pred=model(x_var)
loss=criterion(y_pred,y_var)
optimizer.zero_grad()
loss.backward()
optimizer.step()Pretrained Model 사용하는법은 다음과 같다.

visdom을 이용해서 시각화도 가능하다.
텐서플로우와 파이토치 비교
Static (텐서플로우)
-그래프 하나 고정
- 해당 그래프 최적화 가능
- 원본 코드 없이도 그래프 다시 불러오기 가능
- 조건부 연산 그래프 따로 만들어야해
Dynamic (파이토치)
- forward pass할때마다 새로운 그래프 구성
- 최적화 어려움
- 모델 재사용을 위해서는 항상 원본 코드가 필요
- 코드가 깔끔하고 작성하기 쉽다. (조건부 연산 파이썬 if문)
- dynamic은 RNN에 요긴하게 사용됨
Caffe
- 코드작성 없이도 네트워크 학습이 가능하다.
- feed forward 모델에 적합하다
- prodiction의 측면에 적합하다
Caffe2
static graph 지원
코어는 C++로 작성되어 있고 python 인터페이스 제공
- 딥러닝이 필요한 모든 곳에서 동작하는 프레임워크를 만들고 싶어함
- pythorch는 연구에 특화
- caffe2가 제품개발에 사용됨
9강에서 만나용ㅇ
'컴퓨터공학' 카테고리의 다른 글
| [프로그래머스/C++] 내적 (0) | 2021.09.12 |
|---|---|
| [CS231n 9강 정리] CNN Architectures (1) | 2021.08.18 |
| [CS231n 7강 정리] 신경망 학습 (Training Neural Networks II) (0) | 2021.08.16 |
| [CS231n 6강 정리] 신경망 학습 (Training Neural Networks) (0) | 2021.08.16 |
| [CS231n 5강 정리] CNN(Convolutional Neural Network) (0) | 2021.08.15 |


