
오늘은 CNN 아키텍쳐들에 대해서 알아보겠습니다.
LeNet-5
- 산업에 성공적으로 적용된 최초의 convNet
- 이미지를 입력으로 받아 stride=1인 5X5 필터를 거치고 몇개의 conv와 pooling layer을 거침
- 마지막에 FC
2012년 AlexNet
- 최초의 large scale CNN
- ImageNet Classification Task 성능 좋음
- ConvNet 연구 유행시작

위와 같은 레이어들로 이루어져 있다. 슬라이드에 output volume과 파라미터 개수에 대한 간단한 퀴즈가 있다. 까먹을 때 참고하면 좋을거 같다.
tips
- pooling layer에는 파라미터가 없다.
- 실제 입력은 227x227
- 총 파라미터 60M


그당시 GTX 580을 사용했고, 메모리가 3GB밖에 되지 않았기 때문에 전체 레이어를 single GPU안에 넣을 수 없었다. 따라서 2개의 GPU에 feature map을 반씩 분산시켜 넣었다.

conv1,2,4,5의 경우 같은 오직 gpu의 featuremap들과 연결되어 있고, conv3, fc 6,7,8의 경우 gpu간의 통신을 통해 전체 featuremap과 연결되어 있는 것을 볼 수 있다.
ZFNet
- Alexnet의 하이퍼파라미터를 개션
- Alexnet과 레이어 수도 같고 구조도 같다.

2014년도에 들어서 레이어수가 19,22로 늘어났다. 2014년도 우승자는 Google의 Googlenet이었다. 2등은 옥스포드의 VGGNet이 수상했다
VGGNet
- 훨씬 깊어짐
- 작은 필터 3x3 -> Depth를 더 키울 수 있다
Receptive Field = filter가 한번에 볼 수 있는 Sparical area

3x3 필터 3개와 7x7 하나의 receptive field는 같다. 작은 필터를 써서 parameter도 줄이고 비선형성을 더 추가하게 되고 더 깊게 만들 수 있다.

하지만 이미지 하나당 100MB라면 50장밖에 처리못함.
Q. Depth를 늘리는 이유
- 계산량을 일정하게 유지시키기 위해서
tips
- 초기 레이어들이 메모리 사용량이 많다. sparial dimeation이 큰 곳들에 메모리 사용량이 많다.
conv3-64 = 64개의 필터를 가진 3x3 conv 필터

GoogleNet

Inception module을 여러개 쌓아서 만든다.
파라미터를 줄이기 위해 FC 레이어를 없앴지만, 더 깊게 구현했다.
그래서 inception module 이란?

구글은 good local network typology를 만들고 싶었다고 한다. network안에 network느낌으로 local topology를 만들었고, 이 네트워크를 inception module이라고 한다.
동일한 입력을 받는 여러개의 필터들이 병렬로 존재하고, 각각의 출력값들을 depth 방향으로 합치고, 이 합쳐진 하나의 tensor을 다음 레이어로 전달하는 방식이다.
문제점
volume을 한번 계산해보자.

zero padding으로 조절해가며 spatial dimention을 맞추어주면 다음과 같이되고, 최종적으로 28x28x672의 volume이 나온다. spatial dimention은 변하지 않았지만 depth가 엄청나게 늘어난것!
이때 발생하는 문제점은 계산량이 무지 많아진다는 것이다.

그에 대한 솔루션은 다음과 같다. 1x1 conv 필터를 이용해서 입력의 depth를 줄여 연산량을 줄일 수 있다.

1x1 conv로 인해 정보손실이 있을 수 있으나 redundancy가 있는 input features들을 선형결합하는 것이고, 연산량을 줄여 다른 곳에 비선형 레이어를 추가함으로서 더 잘 동작하게 할 수 있다.
전체구조를 한번 보자



초반에는 우리가 일반적으로 보던 레이어들로 구성되어있다.
중반부에는 inception module이 쌓아져 있다.
결론적으로 classifier output이 나오게 된다.
하나 더 봐야 할 것은 googlenet 같은 경우 auxiliary classifier가 존재한다.

네모 친 미니 네트워크들에서도 loss를 계산하는데, 이는 전체네트워크가 깊기때문에 그레디언트 값이 점점 작아져 0이 되는 것을 방지하여 중간 레이어들의 학습을 도와주는 역할을 한다.
Resnet
- 엄청 깊어짐
- residual connections 사용

그들이 가진 의문점은 이렇다
- CNN을 깊고 더 깊게 쌓게 되면 어떤 일이 벌어질까?

위의 그래프를 보면 test error의 경우 56레이어가 20레이어보다 안좋다. training error을 살펴보면, 56layer에서 많은 파라미터가 있음에도 불구하고 overfit이 되지 않고 traiing error가 높은 것을 볼 수 있다. 이 실험을 통해 더 깊은 모델이 test 성능이 안좋게 나오는 것은 overfitting 때문이 아니라고 생각한다.
Resnet 저자들은 이것이 optimization의 문제라고 생각을 했다. 모델이 깊어질수록 최적화가 어려워지는 것이라 생각을 했다.
그들은 또 모델이 깊다면 최소한 더 shallow한 모델의 성능만큼은 나와야 하지 않는지에 대한 의문을 제기했다. 이러한 생각으로부터 다음과 같은 residual mapping 아이디어가 착안되었다.
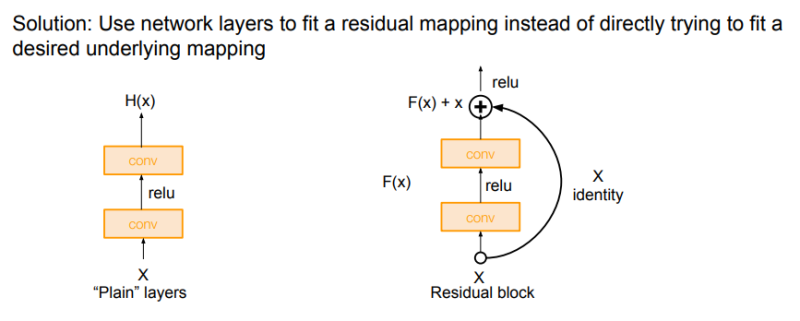
그들은 output H(x)를 학습시키는 것 보다 변화량 F(x)를 학습시키는 것이 더 쉬울 것이라 판단, 오른쪽 커브 화살표인 가중치가 없는 Skip connection을 추가하여 구성했다. residual이 학습이 더 잘되냐?는 가설일 뿐이지만 그들은 레이어가 잘 동작하려면 레이어의 출력이 identity에 가까워야 한다는 가설을 세우고 진행했다. 실제 그 가설이 맞는지는 모르나 ResNet을 추가하면 성능 향상이 두드러진다.
전체 Resnet 아키텍쳐는 다음과 같다.

슬라이드에 잘 설명되어있음
하나 추가하자면 Global Average Pooling Layer(GAP) : Map 전체를 Average Pooling함

Depth가 50 이상일 때 Bottleneck layer을 추가. 3x3 conv의 연산량을 줄임

실험 설정은 위와 같다.

실험결과는 위와 같다.
최근 Resnet을 많이 이용하고 있다.
모델 별 complexity

Google-inception v4(Resnet+inception) 이 가장 좋은 모델.
오른쪽 그래프의 x축은 연산량, y축은 accuracy이다. 원의 크기는 메모리 사용량이다.
VGGNet: 효율성 작음. 메모리 효율 안좋고 계산량도 많다. but 성능은 봐줄만함
googlenet: 효율적.메모리 사용도 적다.
Alexnet: 초기모델인지라 성능 안좋음
Resnet: 적당한 효율성. accuracy 최상위

왼쪽 그래프는 forward pass 시간 그래프, 오른쪽은 전력소모량
Network in Network(NiN)
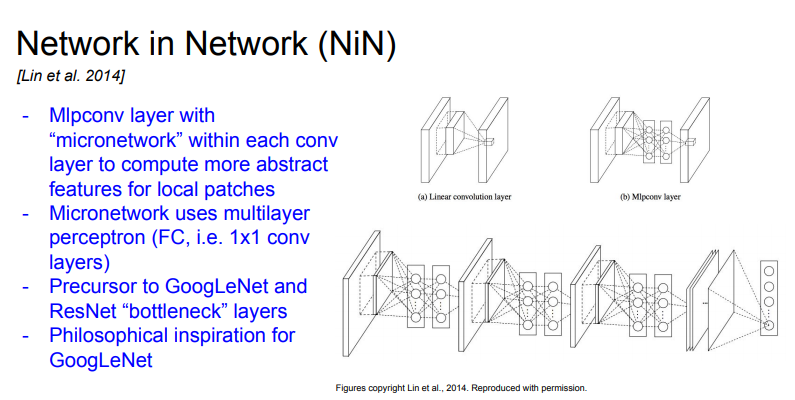
각 conv layer안에 Multi layer perceptron(FC)을 쌓아서 네트워크 안에 작은 네트워크를 만드는 방식. FC layer, 즉 1x1 conv layer을 사용해서 abstract features을 더 잘 뽑을 수 있도록 하고자 함. googlenet, resnet보다 먼저 보틀넥의 개념 정립
ResNet 블록 향상

direct path를 늘려서 forward, backprop이 더 잘 될 수 있도록 설계

사실 resnet에서 depth가 아닌 residual이 중요하다고 주장. residual block의 conv layer 필터를 더 많이 추가해서 더 넓게 만들었다. 각 레이어가 넓어져서 50레이어만 있어도 152 레이어의 기존 성능보다 좋음
filter의 width를 늘리면 병렬화가 더 잘되어서 계산 효율이 증가해서 좋음.

ResNet+Inception
residual block 내에 다중 병렬 경로를 추가함. 마찬가지로 width늘리기

이번엔 Depth를 타깃으로 한 논문이다. 네트워크가 깊어질수록 Vanishing gradient 문제가 발생한다. train time에 일부 네트워크를 골라서 identity connection으로 만듬. shorter network가 되어 그래디언트가 더 잘 전달될 수 있다. Dropout과 유사. test time에는 full deep network 사용

residual connection이 쓸모없다 주장. shallow/deep 경로를 출력에 모두 연결. train time에는 일부 경로만으로 학습. 성능 좋음

네트워크의 input 이미지가 모든 레이어의 input으로 들어감. 모든 레이어의 출력이 각 레이어의 출력과 concat됨. Dense connection이 vanishing gradient 문제를 해결할 수 있다고 주장. Dense connection이 Feature을 더 잘 전달하고 사용할 수 있게 해준다.

Imagenet에서 Alexnet 만큼의 accuracy를 보였지만 파라미터는 50배 더 적었음.용량 상당히 작다.
위의 모델들은 Model zoo에서 언제든지 가져다 쓰면 된다.
10강으로 찾아뵙겠습니다아 :)
'컴퓨터공학' 카테고리의 다른 글
| [프로그래머스/C++] K번째수 (0) | 2021.09.12 |
|---|---|
| [프로그래머스/C++] 내적 (0) | 2021.09.12 |
| [CS231n 8강 정리] 딥러닝 소프트웨어 (Deep learning software) (0) | 2021.08.16 |
| [CS231n 7강 정리] 신경망 학습 (Training Neural Networks II) (0) | 2021.08.16 |
| [CS231n 6강 정리] 신경망 학습 (Training Neural Networks) (0) | 2021.08.16 |

