
지난시간까지 w와 스코어, loss function, 그리고 gradient를 배웠습니다. 오늘은 이제 실제로 analytic gradient(앞 강의에서 설명한 해석적 방식) 를 어떻게 계산하는지에 대해서 알아봅시다.
역전파(Back Propagation)
먼저, computational graph에 대한 이해가 필요합니다. 아주 쉬워요. 보시면 앞서 배운 과정들을 바로 떠올릴 수 있습니다. 아래와 같이 연산자와 피연산자들을 각 노드에 배치하여 함수를 완성하면 됩니다.

이제 이 그래프를 가지고 역전파(backpropagation)를 계산해봅시다. 역전파는 gradient를 얻기 위해서 chain rule을 사용하는데요, 대략적인 순서는 다음과 같습니다.
- 함수에 대한 computational graph 만들기
- 각 local gradient 구해놓기
- chain rule
- z에 대한 최종 loss L은 이미 계산되어 있다.
- 최종 목적지는 input에 대한 gradient를 구하는 것
예제를 바로 풀어보겠습니다.
문제 1
풀이과정)
답)
어떤 복잡한 함수가 와도 local gradient를 구하고 chain rule을 이용하면 된다.
몇가지 게이트 법칙
- add gate: 비율만큼 나눠줌
- max gate: 하나만 실제로 영향을 주는 값이다. 그쪽만 gradient 가짐
- 하나의 노드에서 forward로 Multi로 나가면 역전파할때 gradient 더해줘야됨
문제 2
풀이과정)
답)
이제 인풋이 벡터인 경우를 생각해보자. 과정은 다 같으나 gradient이 아닌 Jacobian을 계산해주면 된다. 또한 입력의 각 요소는 출력의 해당 요소에만 영향을 주므로, 대각행렬이다.
문제 3
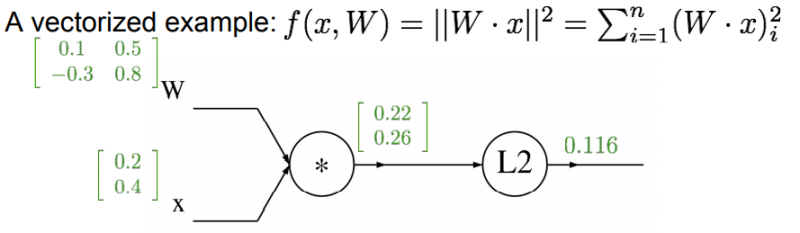
풀이과정)

답)
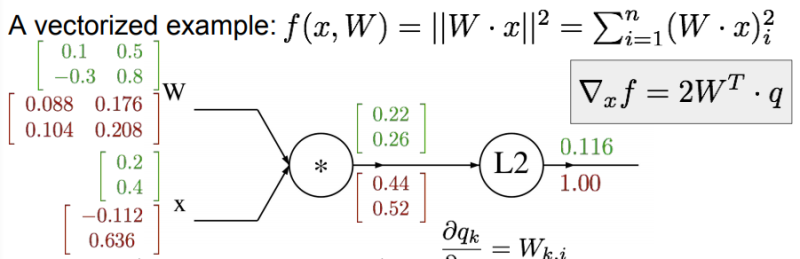
벡터의 gradient는 항상 원본 벡터의 사이즈와 같다. 검산시에 꼭 확인하자.
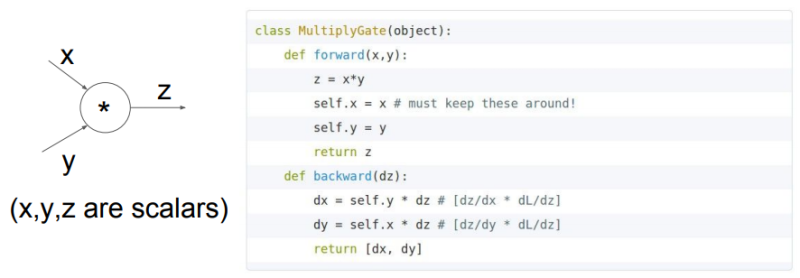
곱셈 게이트에 대한 forward와 backward pass의 파이썬 구현은 다음과 같이 할 수 있다.
딥러닝 프레임워크 라이브러리 Caffe
GitHub - BVLC/caffe: Caffe: a fast open framework for deep learning.
Caffe: a fast open framework for deep learning. Contribute to BVLC/caffe development by creating an account on GitHub.
github.com
신경망(Neural Network)
지금까지는 layer가 하나짜리인 linear function만을 이용했습니다. 이제는 Single 변환이 아닌 그 이상의 레이어들을 쌓아봅시다. 아래와 같이 계속 쌓을 수 있습니다.
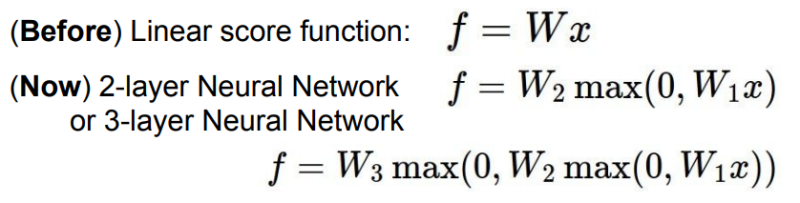
max와 같은 비선형 레이어를 추가할 수 있다.
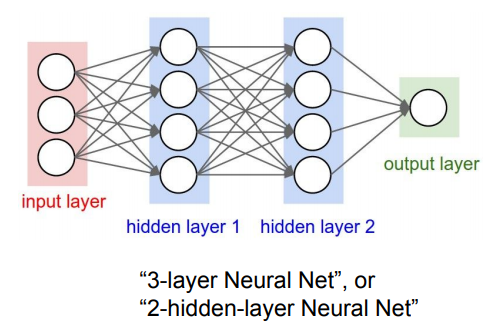
중간에 있는 레이어들을 hidden layer라 부릅니다.
나중에 더 다룰 여러 Activation functions

5강으로 오겠습니다! 안녕
[CS231n 5강 정리] CNN(Convolutional Neural Network)
4강에서 놓친부분들이 몇개 있어 정리하고 가려 합니다. 지난시간에 다중 레이어를 배웠고, linear layer과 non-linear layer들을 조합하여 신경망을 만들었습니다. 이는 Mode 문제를 해결함으로써 빨간
oculus.tistory.com
'컴퓨터공학' 카테고리의 다른 글
| [CS231n 6강 정리] 신경망 학습 (Training Neural Networks) (0) | 2021.08.16 |
|---|---|
| [CS231n 5강 정리] CNN(Convolutional Neural Network) (0) | 2021.08.15 |
| [CS231n 3강 정리] 손실함수(Loss functions), 최적화(Optimization) (1) | 2021.08.15 |
| [CS231n 2강 정리] NN,K-NN, Linear Classification (2) | 2021.08.15 |
| [CS231n 1강 정리] 컴퓨터 비전의 역사 (1) | 2021.08.15 |



